
阿里开源最新推理模型:性能媲美DeepSeek-R1,但参数不到5%,强化学习再立大功

出品 | 搜狐科技
作者 | 梁昌均
在DeepSeek成为新晋“源神”后,国内此前的开源领头羊阿里加快追赶。
这不,阿里通义团队又上新了。这次他们推出最新推理模型QwQ-32B。这是一款拥有320亿参数的模型,其性能可与具备6710亿参数(其中370亿被激活)的DeepSeek-R1媲美。
这意味着,QwQ-32B用不到5%的参数规模,达到了DeepSeek-R1的相同性能。“这一成果突显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。”通义团队表示。
继深度学习之后,强化学习正在成为影响AI技术发展的关键驱动力,DeepSeek、OpenAI、谷歌等此前均因此受益。
最近官宣的2024年图灵奖,“强化学习之父”理查德·萨顿(Richard S. Sutton)及其76岁的导师安德鲁·巴托(Andrew G. Barto),凭借奠基研发强化学习技术而共同获奖。
图灵奖被誉为“计算机领域的诺贝尔奖”,如今颁给强化学习奠基人,一定程度也证明了,AI的强化学习时代,真的来了。
阿里通义团队更是表示,相信将更强大的基础模型与依托规模化计算资源的强化学习相结合,会更接近实现通用人工智能(AGI)。
性能媲美DeepSeek-R1,开放力度没DeepSeek大
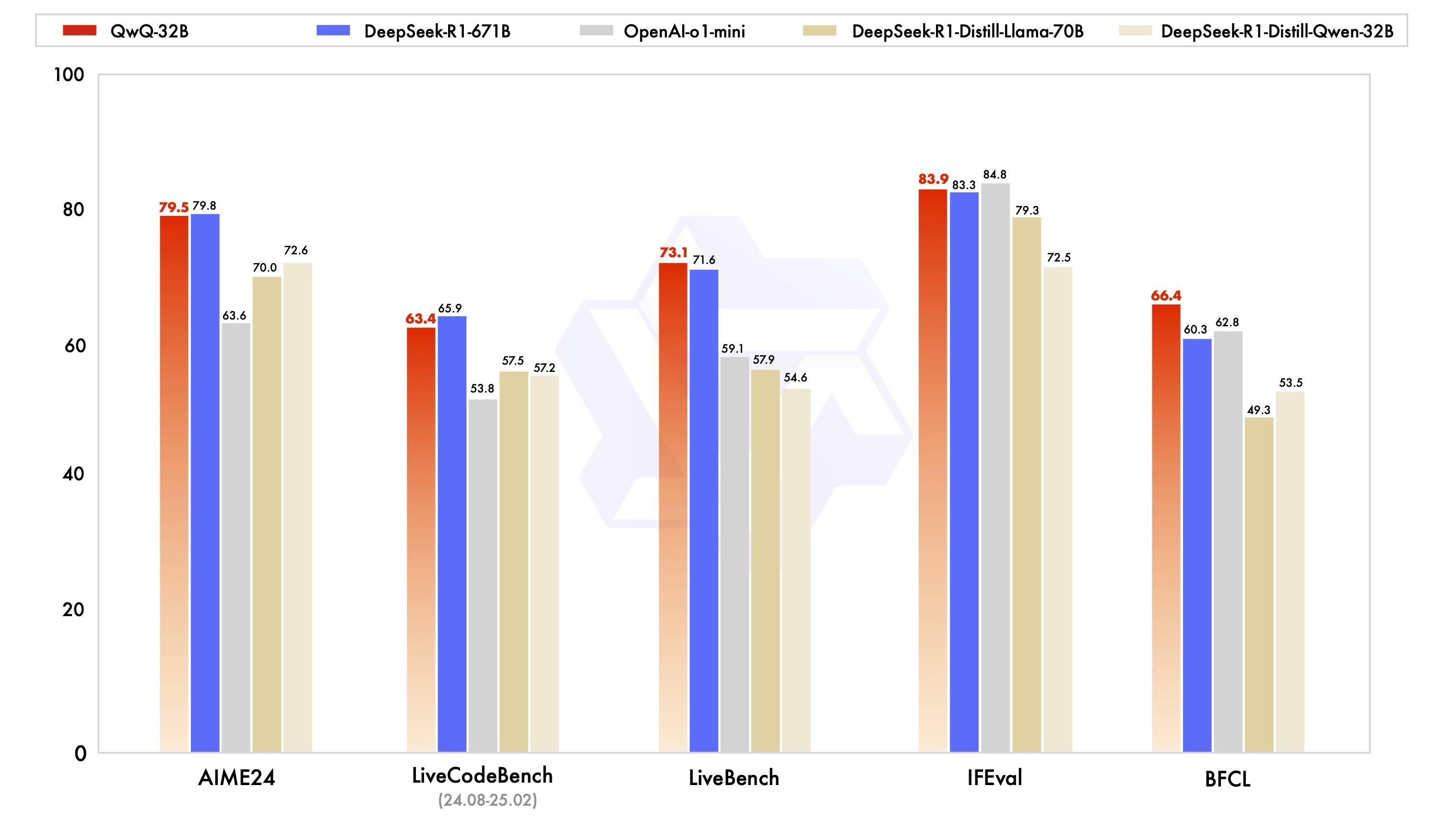
根据阿里通义团队公布的系列基准测试,包括数学推理(AIME2024)、编程能力( LiveCodeBench )和通用能力(LiveBench)等,QwQ-32B均接近或超过满血版的DeepSeek-R1-671B模型,同时远超过OpenAI-o1-mini,以及R1蒸馏模型。
展开全文
其中在被业内评为“最难LLMs评测榜”的LiveBench上,QwQ-32B超过了R1。该测评基准由图灵奖得主、Meta首席科学家杨立昆联合纽约大学等推出,从多个复杂维度对模型进行评估,包括数学、推理、编程、语言理解、指令遵循和数据分析等。
此外,在谷歌等提出的指令遵循能力IFEval评测集,以及加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,QwQ-32B的得分也均超越了DeepSeek- R1。在更小尺寸模型上,实现了更强性能。
目前,该模型已上线阿里云平台,开发者可在云端部署,并进行模型微调、评测和应用搭建。同时,由于更低参数,QwQ-32B还能满足更低的资源消耗需求,可以在消费级显卡上实现本地部署,适合快速响应或对数据安全要求高的应用场景。
不少网友反馈,苹果Mac就可跑这款模型。而要高效运行DeepSeek模型,至少需要22台服务器(每台8张GPU)。相比之下,QwQ-32B大大降低了推理部署的成本门槛。
同时,QwQ-32B已在 Hugging Face和 ModelScope开源,并采用了Apache 2.0开源协议,所有人都可免费下载及商用。
Apache 2.0是 Apache软件基金会发布的开源许可证,是一个相对宽松的许可证,开发者可以自由地使用、修改和分发软件,适用于商业项目,同时也有附加条款,如开发者要保留版权声明、许可证文本和NOTICE文件,并包含专利授权条款,从而既提供了灵活性,又确保了合规性和专利安全,成为很多开源项目的首选。
对比来看,DeepSeek-R1模型则使用MIT开源协议,完全开源,不限制商用,无需申请,同时产品协议明确可模型蒸馏,允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
相较而言,MIT许可证是最简单和宽松的开源协议,许可证文本更为简洁,没有专利授权和商标使用等复杂条款,因此更适合快速开发和商业化。这也是为什么DeepSeek-R1发布后,国内上百家企业都能够迅速接入、推动商用的原因。
此外,DeepSeek此前通过开源周公布了覆盖算力、通信与存储等关键领域的代码库,将降低硬件适配门槛、提高模型训练与推理效率的方法公之于众,成为当之无愧的“源神”。
对比来看,通义团队此次并未公布QwQ-32B有关论文和具体训练方法,在开放开源程度上相对较弱。不过,从规模看,阿里则是当之无愧的开源领头羊。
从2023年至今,阿里通义已开源200多款模型,包含大语言模型千问及视觉生成模型万相等两大基模系列,覆盖从0.5B到110B等参数。目前,千问的全球衍生模型已突破9万个,超越Llama系列,成为全球最大的开源模型族群。
跟多的对手在追刚。智谱此前表示,今年将是开源年,将会发布全新大模型(包括基座模型、推理模型、多模态模型、Agent等)并将其开源。百度也宣布,即将发布的文心大模型4.5也会开源,国内开源模型的竞争将会进一步加剧。
强化学习又立大功,迈向AGI的可行之路?
如何实现更小尺寸模型,达到更强性能?阿里通义团队借助了强化学习(RL)的力量。
此前,DeepSeek-R1借助强化学习,通过整合冷启动数据和多阶段训练,跳过无监督微调,使模型能够进行深度思考和复杂推理。
QwQ-32B此次则重点探讨了大规模强化学习对大语言模型的智能的提升作用。通义团队介绍,该模型在冷启动基础上,针对数学和编程任务、通用能力分别进行了两轮大规模强化学习,从而获得了令人惊喜的推理能力提升,应证了大规模强化学习可显著提高模型性能。
在初始阶段,团队针对数学和编程任务进行强化学习的训练过程中,与依赖传统的奖励模型(reward model)不同,通过校验生成答案的正确性提供反馈。随着强化学习拓展和训练轮次的推进,这两个领域中的性能均表现出持续的提升。
在第一阶段的强化学习过后,通义团队又增加了针对通用能力的强化学习,并使用通用奖励模型和基于规则的验证器进行训练。最终发现,通过少量步骤的通用强化学习,可以提升通用能力,且数学和编程任务上的性能没有显著下降。
此外,QwQ-32B模型中还集成了与智能体Agent相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。
不过,不同于DeepSeek-R1,QwQ-32B是一个密集模型,未采用MoE结构(专家模型),并支持131k的上下文长度,比R1的128k略长。
“这是通义在大规模强化学习以增强推理能力方面的第一步。我们不仅见证了扩展强化学习的巨大潜力,还认识到预训练语言模型中尚未开发的可能性。”阿里通义团队表示,将积极探索将智能体与强化学习集成,目标是通过推理时间扩展来释放更高的智能。
目前,智能体被视为大模型超级应用的突破点。今日发布的号称世界首个通用智能体产品的Manus,引发关注。如何将智能体与强化学习集成,能否显著提升模型性能,还有待验证。
随着OpenAI、谷歌、DeepSeek、阿里等团队推理模型的研究实践,强化学习已经成为驱动AI智能提升的核心。它曾于2016年在AlphaGo上展现出巨大威力,如今再一次放出光芒。
这在学术界也得到认可。最近,美国计算机学会ACM宣布,理查德·萨顿及安德鲁·巴托为2024年ACM图灵奖获得者,以表彰他们为强化学习奠定了概念和算法基础,早年的“冷板凳”算是得到了正名。

1998年,两人共同撰写了奠基之作《强化学习导论》,并被引用接近8万次。后来,强化学习还与深度学习(由2018年图灵奖得主Yoshua Bengio、Geoffrey Hinton和Yann LeCun研究)结合,催生了深度强化学习技术。
因此,萨顿在业内也被称为“强化学习之父”。获奖后,他引用了艾伦·图灵的名言称:“我们想要的是一台能从经验中学习的机器。”
在萨顿看来,强化学习的核心,是确保机器从经验中学习,或者理解反馈并从错误中学习,而此前的AI路线只是在模仿人类的行为或经验。
强化学习的代表作,除了AlphaGo,ChatGPT实际上也采用了基于人类反馈的强化学习(RLHF)技术。DeepSeek则向前推了一步,利用纯强化学习得到了性能先进的模型,通义此次则又在大规模强化学习探索上迈了一步。
谷歌高级副总裁Jeff Dean认为,强化学习是AI热潮的核心支柱,带来了重大进展,吸引了大批年轻研究人员,强化学习的影响在未来仍将持续。而萨顿很早就提出,强化学习才是AI的未来。
“希望我们的一点努力能够证明,强大的基础模型叠加大规模强化学习也许是一条通往通用人工智能的可行之路。”阿里通义团队表示。
技术的进步是无止境的,而更多的创新将会涌现。








评论